Reflection
The Good, The Bad, The Ugly of Being a Data Engineer
I loved being a data engineer. I'd never do it again.
I worked as a data engineer for 4 years, and I’ve been a software engineer for the past 3 years.
I loved being a data engineer.
I’d never do it again.
This is my raw and honest take on why.
The Good
There are many perks of being a data engineer. Let’s start with the best one.
You Work with Data
I always found working with data to be fun. It’s even better when the data is too large for any single machine and you need distributed systems just to process it.
As a data engineer, you collaborate with analysts to extract insights that steer the company in better directions. Unlike backend work that ships individual features, you build infrastructure that processes millions of events and answers questions that shape strategic decisions.
Which leads to my second point:
Better Business Understanding
If you’re like me (naturally curious about not only the tech, but also the business), you’ll enjoy being a data engineer.
When you’re a backend/frontend developer, you’re focused on your own scope or feature. As a data engineer, you automatically learn about the business. You need a basic understanding of business intelligence to build data pipelines for business intelligence. So you learn.
Your company’s data ranges widely from marketing, user acquisition data, infrastructure, revenue, user statistics, and much more.
As a data engineer, I had to gather data from countless sources: both internal logs we generated and external third-party data from the App Store/Play Store, Mobile Ad SDK providers, marketing channels like Google and Meta, foreign exchanges rate data, and more. When I integrated mobile Ad related data, I had to understand how the mobile Ad industry works. How a gaming studio gains users through mobile ads, how the ad bidding works, and of course all the acronyms (CPI, CPC, CTR, ROAS, ARPU, etc.)
When building retention dashboards, I learned about cohort analysis, how product teams measure user engagement, and what metrics actually matter for growth (D1/D7/D30 retention, stickiness ratios, activation rates).
When working on revenue pipelines, I learned how different monetization strategies work: subscription tiers, in-app purchases, ad revenue waterfalls. I also learned how finance teams calculate LTV (Lifetime Value) to CAC (Customer Acquisition Cost) ratios to determine unit economics.
When supporting A/B testing infrastructure, I learned how product managers think about statistical significance, sample sizes, and how they balance shipping fast versus getting reliable data.
I know many engineers are not fond of dealing with the business side. If you’re like me and are curious to understand marketing, A/B tests, product development, and business in general, being a data engineer is great.
Technical Freedom and Full-Stack Ownership
Unlike product engineers, data engineers enjoy unusual autonomy in two distinct ways.
First, you have technical freedom. Since most data engineering work serves internal teams rather than end users, the stakes are different. Product engineers building user-facing features must be conservative with their tech stack and extremely cautious about downtime. One bad deploy could affect millions of users.
Data engineers can afford to be more adventurous:
- Want to try a new open source data quality tool? Go for it.
- Curious if rewriting that Python pipeline in Scala would make it 10x faster? Spin up a test environment and find out.
- Interested in switching from AWS EMR to Databricks? You have the freedom to prototype and compare. (maybe)
If something breaks at 2 AM, it affects your data analyst colleagues, not millions of end users. The blast radius is contained.
Second, you get full-stack ownership. Product team roles are specialized. Backend engineers write code, DevOps/SREs manage infrastructure. Data engineers typically do everything. You write the pipeline code and spin up the Kubernetes cluster to host your Airflow, Superset, and data lineage tools.
This varies by organization, but from conversations with dozens of people across the industry, data engineers predominantly own and operate their own infrastructure.
This breadth teaches you more than just ETL code:
- How modern cloud infrastructure works with tools like Terraform and Pulumi
- What Kubernetes, Helm, and ArgoCD actually do (and why people won’t shut up about them)
- How to build observability with Prometheus, Grafana, and Datadog
You become a generalist by necessity. For someone curious about the full technology stack, this is invaluable experience that most specialized roles simply don’t offer.
Sounds pretty good, right? But like any role, it comes with its own set of challenges.
The Bad
You Work with Data

Data is messy. As the product evolves, features get added or removed. Some tables get removed or their schemas change. The backend team refactors code and updates log structures, sometimes without notifying the data team.
And when data integrity issues appear, they erode trust fast. Stakeholders rely on dashboards to make decisions. When those dashboards show conflicting numbers, suddenly everyone questions the data team’s competence.
Let me paint you a picture of what this looks like in practice:
A Day in the Life
The time is 8PM. A product manager, who has been working overtime for a new feature release, pings you on Slack.
Hey @Jacob, D1 retention on our KPI dashboard says 48%, but D1 retention on our User dashboard says 43%. So which is it?
Now you have to check which data source those two dashboards are pulling from. Then you check the code that builds that derived data, either in SQL, Python, or Scala. Can’t find an issue there either. The code seems fine. All Airflow DAGs are operational. It’s already 9PM, and your brain is not functioning at full capacity. Maybe you should look at this tomorrow with a clear mind.
Then you hear another “Ding” sound from your Slack.
Hey can I just get the raw data in CSV? I don’t want to bother you. I can just run the data on my laptop.
The same PM now asks for the raw data, so he can run the data on his laptop with Excel and Power BI. Now you have to explain that the “raw” data probably won’t fit his laptop’s SSD. And tell him that you will fix the data discrepancy ASAP.
You can sense that the PM’s trust in your data team is diminishing by the minute. And you know from experience that lower trust means more and more of these “raw-data” requests coming. Can’t let this happen.
You dive deep into the pipeline codes. You run the ETL job related to the retention calculation on your Databricks or Snowflake console, and inspect the output manually. Ah, you found an issue.
The server team changed the log structure without notifying anyone.
They renamed signUpAt to signUpTimestamp, but instead of properly migrating the field, they did this:
{
"signUpAt": 0,
"signUpTimestamp": 1759990133
}Both fields exist, but the old signUpAt field now always contains 0, while the new signUpTimestamp has the actual value.
Here’s what happened: Both dashboards read from the same raw data, but they use different ETL pipelines to calculate retention. The KPI dashboard’s pipeline was recently updated by a colleague who noticed the new field and switched to signUpTimestamp. The User dashboard’s pipeline still uses the old signUpAt field. Since signUpAt now returns 0 for all users, that pipeline thinks everyone signed up at epoch time (January 1, 1970), completely breaking the retention calculation.
Anger brews from deep within, but there’s no time for that.
You duck-tape the SQL code and backfill 24 hours worth of data just to be sure.
When the backfill is over, you check the dashboard and now see that the retention numbers are the same between the two dashboards.
Now you ping the PM on Slack to let him know that the issue is resolved and apologize for the data discrepancy. Before you sleep, you create a couple backlog tickets on Jira:
- Add more checks during our data quality check, to catch if a field contains 0 when it should never be zero.
- Communicate with the server team about unsolicited schema change.
That’s just one example. The reality is that data problems like this happen constantly.
You might have to deal with schema designs so atrocious that you want to meet Bob, who designed this schema 6 years ago and left the company 3 years ago.
The server team can forget to mention deprecation of certain log types or fields.
A test user who was supposed to be excluded from the dataset somehow manages to show up on the dashboard and messes with the entire data.
It is your job to deal with these issues in a timely manner, or else the trust of the data engineering team can slowly fade within the org.
Which also leads to my second point:
Constant Fire Fighting

As the company grows, the number of reports and dashboards to support only grows. More data sources need to be connected and maintained. Third-party data source APIs are unreliable and go down frequently, which triggers downstream ETL job failures for whichever jobs rely on that third-party API data. The number of ETL data pipelines only grows and the complexity grows with it. The DAG (directed acyclic graph) is now jarring to look at.
Your team has big dreams of taking the ETL pipeline to the next level. Maybe it’s to make the whole pipeline real-time. Or help with creating new machine learning algorithms.
However, with every growing number of components to support, you spend most of your days just putting out the fire. And it is not fun.
You joined as a data engineer to extract insights from data and steer the org in the right direction. Instead, what you do daily is mostly looking at Airflow error logs.
You decided to take on an initiative to put an end to this. You name it “Durable ETL” project and convince your team to dedicate two sprint cycles on making sure that ETL pipelines are rock-solid. Your colleagues, who were also tired of this constant firefighting, agree. The future looks bright for your data engineering team.
But the fast-paced environment of modern software development knocks down that dream. Jira tickets pile up: new features, new ways to A/B test, new derived data sources for the new dashboard, coming from both product and data analytics team. You tell your boss that your team would like to focus on the “Durable ETL” project. But your boss pays you to help data analysts come up with better insights, not to refactor infrastructure that “already works.”
Fair enough.
You and your team set aside the “Durable ETL” project, and deal with these tickets first. But you promise to get back to this project as soon as you’re done dealing with those tickets. While dealing with the tickets, Airflow job breaks from time-to-time, so you fix that.

You are frustrated with the current company and the management. You want to jump ship. You pull out your old resume. And you remember the things you’ve achieved as a data engineer in that org. And it’s mostly just fixing errors, adding more data pipeline codes, and making minor improvements to the existing data infrastructure.
Boredom
Writing ETL pipeline code is not fun.
The feedback loop is slow. While you can run some sample data on your local machine quickly, you have to ultimately test with the real data on the actual system. Spinning up a spark cluster to test your new ETL job alone could take 3 - 5 minutes. Once they are up, running your ETL job could take minutes to hours even.
For me, when the feedback loop is this slow, I get bored. So I work on a different pipeline code while this ETL job is running. And this constant context switching did not help to get into a flow state which is when I am most productive.
When I first tried web development, the contrast was striking. Every keystroke showed immediate feedback in the browser. No waiting for clusters to spin up, no context switching while jobs run. The tight feedback loop kept me in flow state and made coding genuinely fun again.
Operating vs. Building
As a data engineer, you get to work with great open source programs. Like Spark, Airflow, Superset, Kafka, Iceberg, etc the list goes on. You can become an expert at these programs, know every single JVM config for Spark to optimize your ETL pipeline. Yet, that does not mean you can create one.
Creating this amazing software requires software engineering skills that differ from data engineering work.
Data engineering emphasizes mastery of distributed systems, SQL optimization, and understanding data pipelines, but it’s fundamentally about using sophisticated tools rather than building them. You become an expert operator, not necessarily an expert creator.
For me, the joy of programming is making something that many people can enjoy. What data engineers build is not user-facing. If you call your internal data analysts/data scientists users, then you have about 10-20 users depending on your company’s headcount.
So it limited my ability to build a product. My day-to-day job did not train me on how to build a web service, mobile app, or backend server. I built data pipelines and supporting infrastructure. Of course these are important skills in an enterprise setting, but for someone who wants to ultimately build their own thing, it didn’t help.
Invisibility
Data engineers are like the backend of the backend. How do data engineers contribute to a company? I think there are three main ways.
First is to create data pipelines for reports/dashboards. This way we help data analysts create better reports/dashboards, which in turn help stakeholders (PMs, C-levels) make better decisions. So there are many layers between data engineers and actual business impact.
Second, data engineers enable AI/ML capabilities by building feature stores and real-time inference pipelines. YouTube’s recommendation algorithm, TikTok’s For You page, Amazon’s product recommendation: these are all probably built on top of some sort of real-time data pipeline. With these pipelines, data scientists train machine learning algorithms to inference and serve real-time recommendations to users. This time, the data pipeline has to be real-time and durable compared to the data pipeline used for reporting/dashboard. Downtime in the data pipeline could mean the recommendation engine having failure. However, data engineers are still working behind data scientists.
Third is to build a user-facing data product. For example, building an API service for users. In a gaming company, the data engineering team can provide an open API for game stats, which allows third-party developers to build products on top of it. Products like OP.gg or u.gg are famous examples built on top of game statistics APIs provided by gaming studios. Not many companies have this kind of opportunity for data engineers to build user-facing products, nor is it typically their role.
I am sure there are more ways for data engineers to contribute depending on what kind of org you are at. But these are the ones that I witnessed. Without a doubt, data engineers play an important role in most software orgs, yet it’s tough for data engineers to have more visibility or impact on the org’s grand mission.
The Ugly
The Existential Crisis
Here’s the uncomfortable truth I realized as a data engineer: the decisions that truly transform companies rarely come from the infrastructure I was building.
You spend your career enabling “data-driven decision making.” You build dashboards, optimize pipelines, ensure data quality, all so stakeholders can make informed choices.
Here is a graph of a product’s improvement on the y-axis, and time on the x-axis.
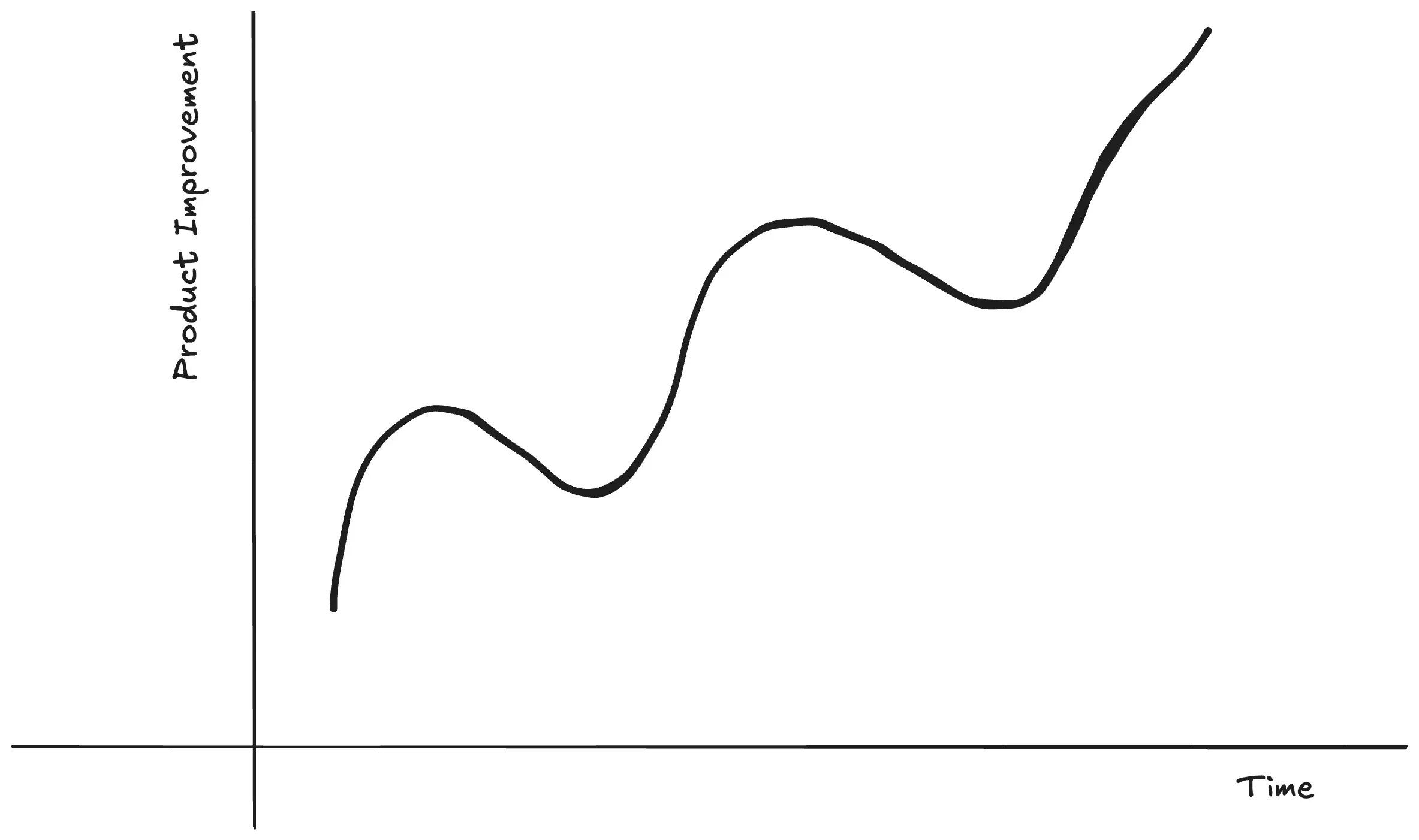
Most products improve as time goes on. (Hopefully)
And being data-driven helps the product reach its local maximum.
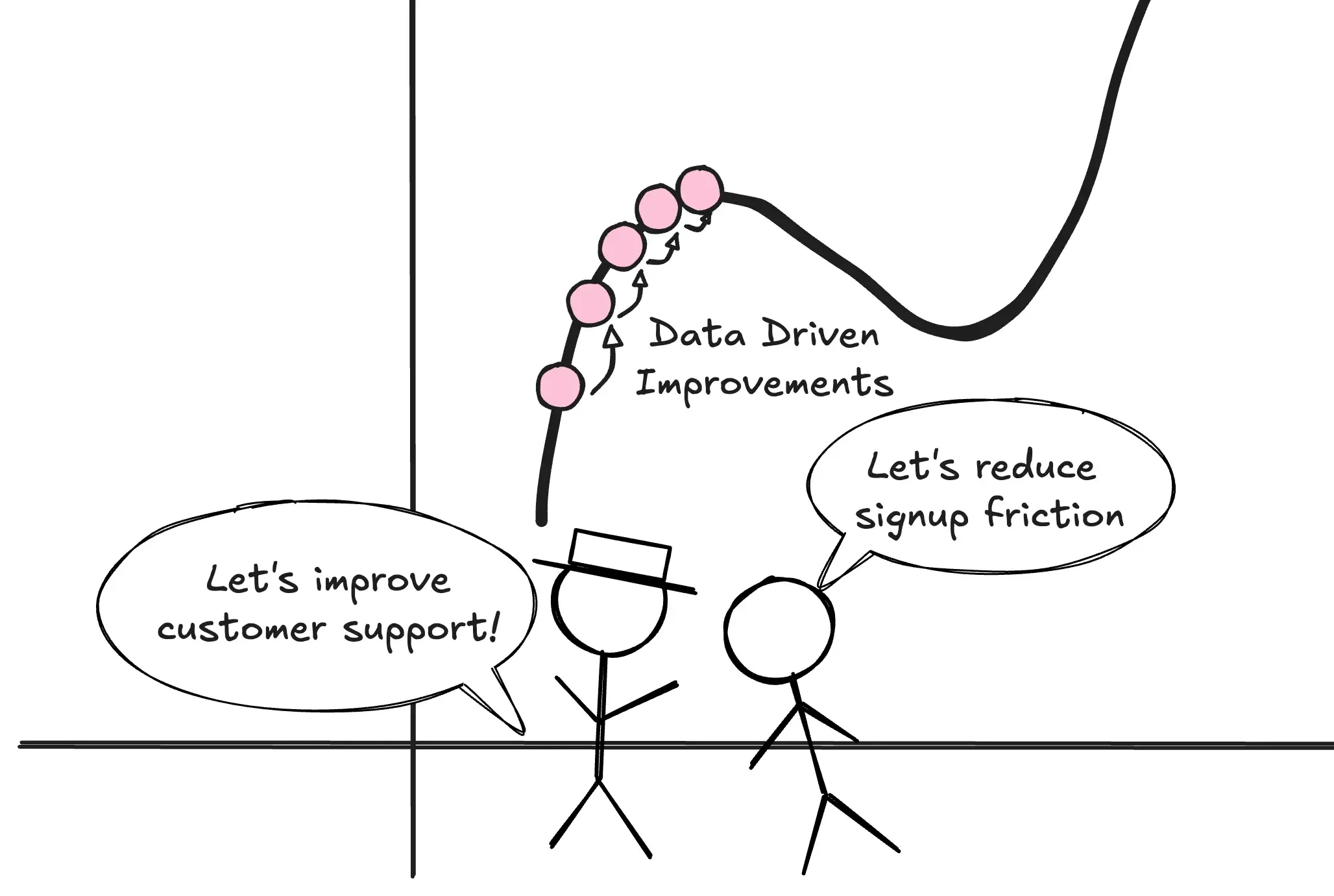
Reducing signup friction by 15%? A/B test it. Improving email open rates by 8%? Dashboard will tell you what worked. Boosting conversion by 3.2%? Data shows you exactly which funnel step to optimize.
These improvements matter. When combined, tens or hundreds of these data-driven optimizations really determine if a product is mature or not.
But here’s what nagged at me: the decisions that jumped companies to entirely different levels didn’t come from dashboards.
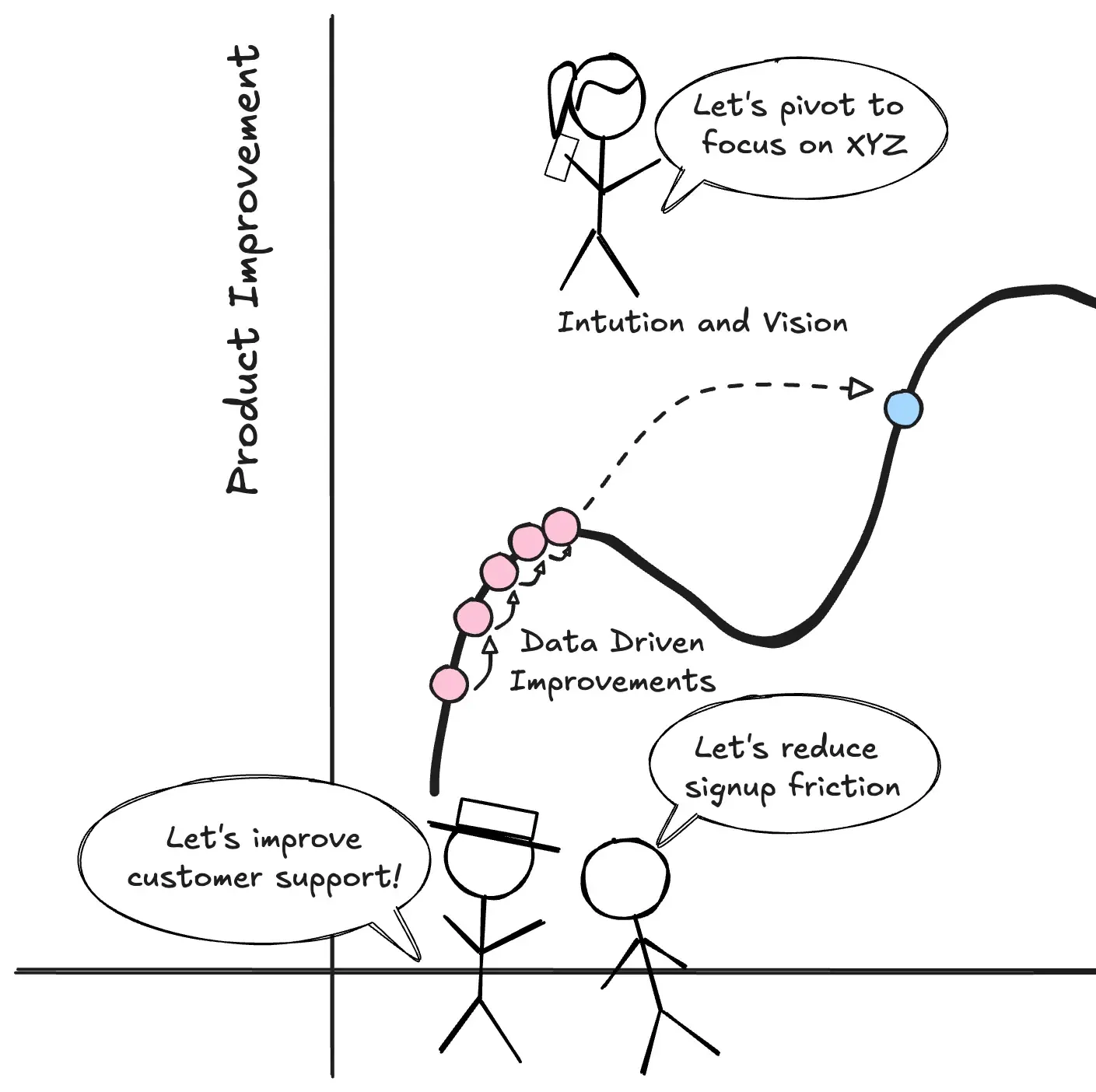
I saw this firsthand at Krafton. The game I worked on, NEW STATE Mobile, didn’t meet expectations. No amount of optimizing user funnels, improving email open rates, or implementing better pricing helped the game win back lost players.
The game industry, like movies and music, is hit-or-miss. Data helps you iterate on what’s already working, but it can’t resurrect a product that missed its mark.
And this pattern isn’t unique to gaming:
Netflix streaming - Hastings planned it since the late 90s when “literally no entertainment was coming into the home on the internet.” DVDs were hugely profitable, but he bet the company’s future on a technology that didn’t have the inventory to stand alone yet.
Airbnb’s professional photography - The founders personally visited New York hosts and noticed the photos looked terrible. They grabbed cameras and started shooting listings themselves. When they measured the results, revenue doubled, but the insight came from being in the room, not from a dashboard.
Instagram’s pivot to photos - Kevin Systrom’s girlfriend wouldn’t post iPhone 4 photos because they didn’t look good. He built the X-Pro II filter on vacation in Mexico to solve that specific problem. Only later did the data show users loved filters. The solution came from observation, not metrics.
Tesla going all-electric - When every other automaker went hybrid as the “safe, data-backed path,” Musk bet entirely on electric. The market research said hybrids. Tesla said full electric or nothing.
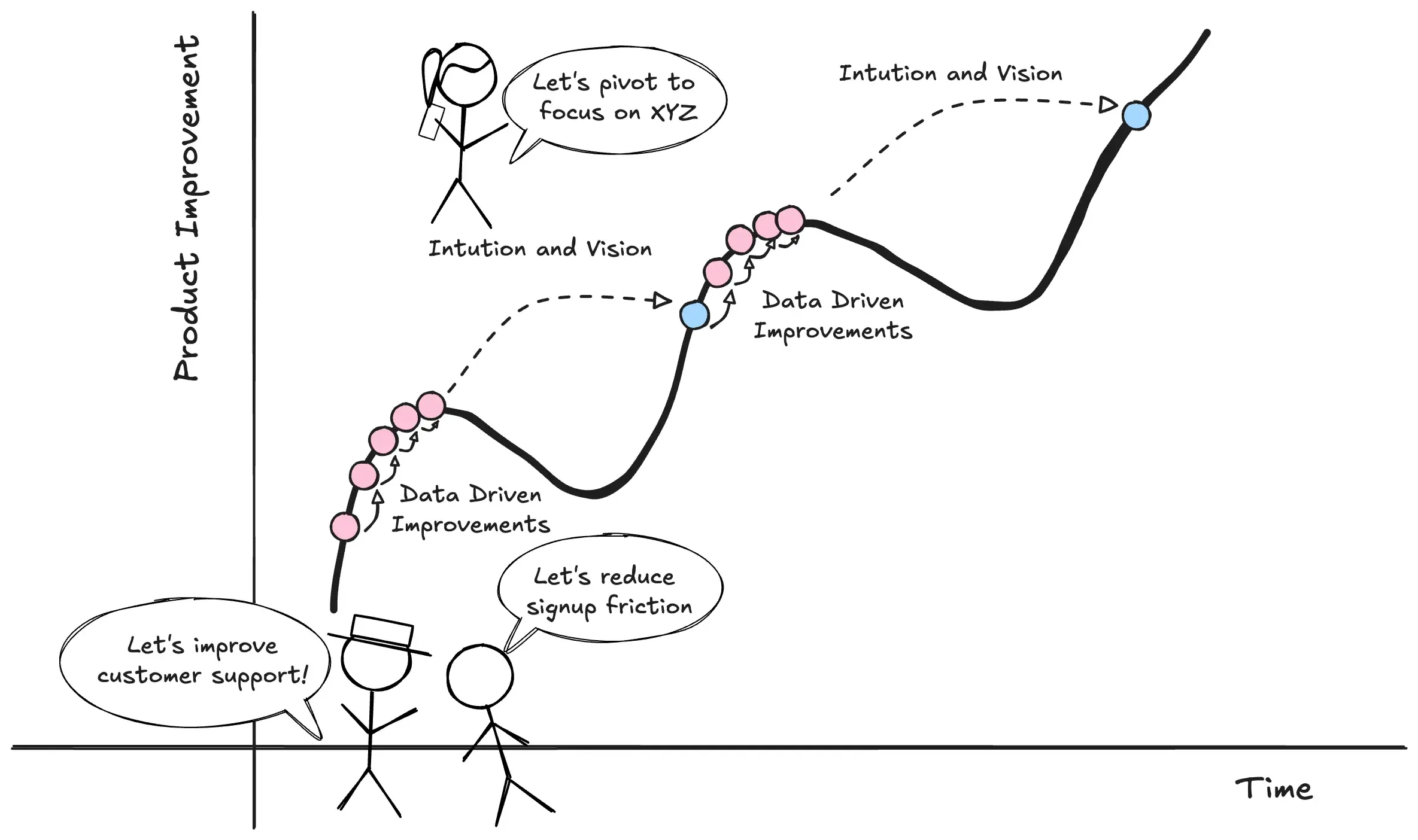
The pattern: intuition spots the new opportunity. Data optimizes execution.
Data helps you climb to the peak of your current hill. It doesn’t tell you there’s a taller mountain next door.
As a data engineer, you’re building tools to perfect the present, not to imagine a different future.
That realization hits different when you’re someone who wants to create something transformative, have real impact on the organization.
Declining Demand for Data Engineers
The data engineer role is getting abstracted away in real-time. And it’s not even about LLMs.
Back in the day, in the Hadoop era, you needed a team of 10 data engineers to manage Hadoop clusters, tune Spark configurations, run Kafka on bare metal, and build orchestration tools out of cron jobs.
By the time I left in 2023, 4-5 data engineers with managed services could do the same work. In 2025, with the advance of LLMs, maybe you need even fewer engineers to do the same work.
Snowflake boasts about minimizing the knobs data engineers need to tune. Databricks makes running and operating Spark so easy. AWS, Confluent, and others turned Kafka, which used to require a dedicated team, into a checkbox on a pricing page. Airflow, which we ran on our Kubernetes, now has a dozen SaaS offerings.
The tools are eating the job.
And unlike other engineering roles where automation creates new opportunities, data engineering’s purpose is fundamentally cost containment. You’re not building the core product. You’re supporting the people who support the people who make strategic decisions.
When a startup founder asks, “Should I hire a data engineer?” the increasingly correct answer is: “Not yet. Use Fivetran + dbt + Snowflake. Hire one when you’re big enough.”
That threshold keeps rising.
For most companies, data engineering is a cost center: necessary but not core. If I were running a startup, I’d minimize spending on data infrastructure and focus on the product. I’d expect any founder to think the same way.
This isn’t happening everywhere at this pace. Backend engineers aren’t being replaced by better frameworks. Frontend engineers aren’t being commoditized by Figma or Webflow. But data analysts can do data engineers’ work with the right tools (unless you are FAANG scale.)
But for data engineers? The Hadoop era needed expertise. The modern data stack needs a credit card.
You feel it when you look at the job lists. The demand is there, but only for massive enterprises with truly complex data problems. For everyone else, the managed services are good enough.
And that’s the ugly truth: you’re in a role where the explicit goal of the industry is to need fewer of you.
So Should You Become a Data Engineer?
Even though I said gloomy stuff, it’s not all that gloomy. The data engineer role is evolving. Some data engineers branch into more AI/ML-focused roles called MLOps. Some do the role of data analyst and become a hybrid between data analyst/engineer. Or you can go hardcore in Spark/Kafka and contribute to open source which is honestly a pretty fun path as well.
On a more personal note, data engineering taught me to think about systems at scale, communicate with non-technical stakeholders, and see how businesses really work. These skills have made me a better software engineer today.
But I wouldn’t do it again.
You’ll thrive as a data engineer if you:
- Want deep business context and enjoy working closely with analysts and PMs
- Love solving messy, real-world operational problems over building new features
- Value technical freedom and experimentation over direct user impact
- See yourself staying in infrastructure/platform roles long-term
Avoid data engineering if you:
- Need fast feedback loops to stay engaged (slow Spark jobs will kill you)
- Want to build user-facing products that millions use
- Dream of creating the next transformative product (you’ll be optimizing, not innovating)
Data engineering isn’t going anywhere. The field is growing, and companies need talented engineers who can wrangle data at scale. Just make sure it’s actually what you want to do.